Stage 1: Single Server Simple, Until It Crashed
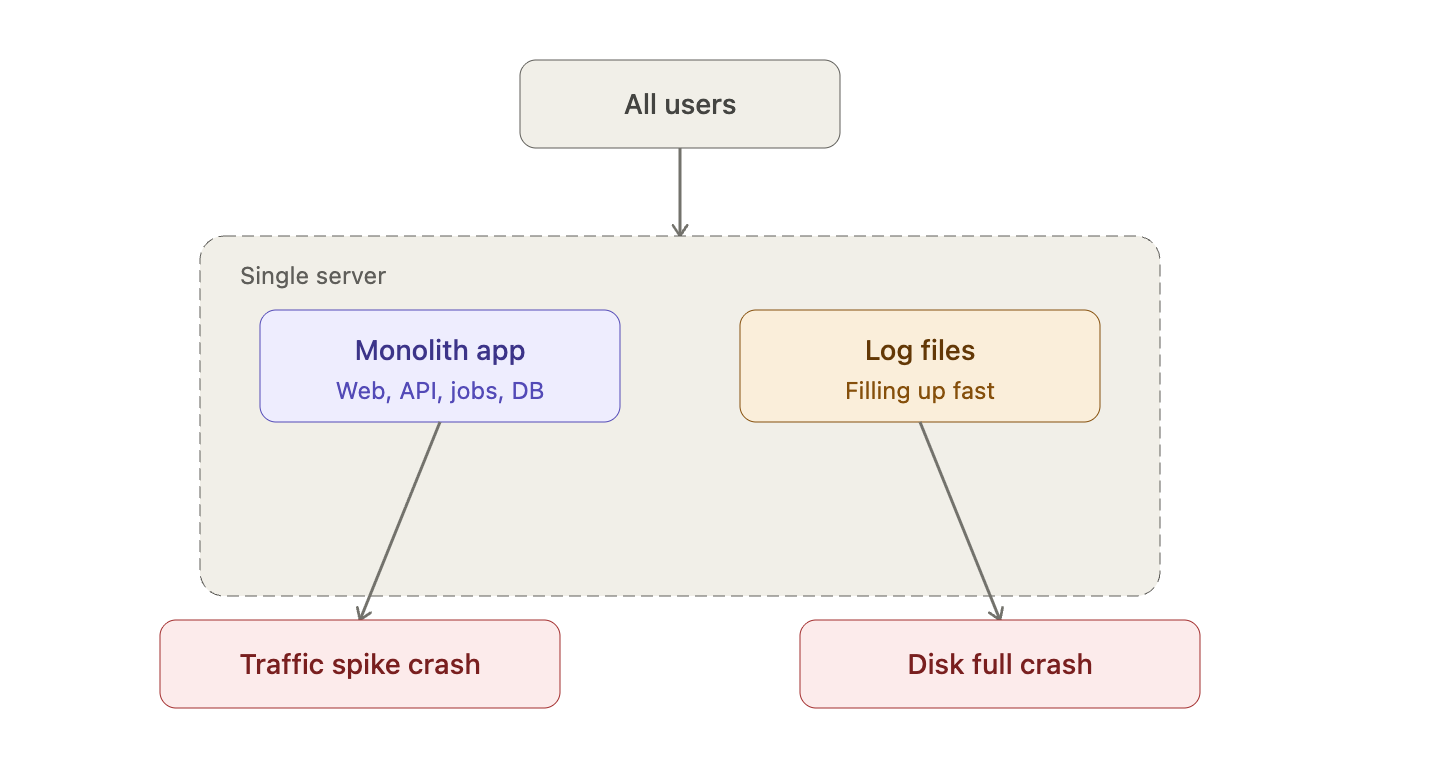
We ran the entire platform on one machine. App, database, background jobs, logs all of it together.
It worked fine early on. Then it didn't.
What broke:
- Logs filled the disk → full crash, every customer down
- Traffic spikes → pages timed out, APIs failed
- One bug in any module → entire platform offline
- Vertical scaling only → paying for an expensive server 24/7, even at 3am on a Sunday
There was no flexibility. No fault isolation. No way to scale down.
Stage 2: Managed Instance Groups Horizontal Scaling, New Problems
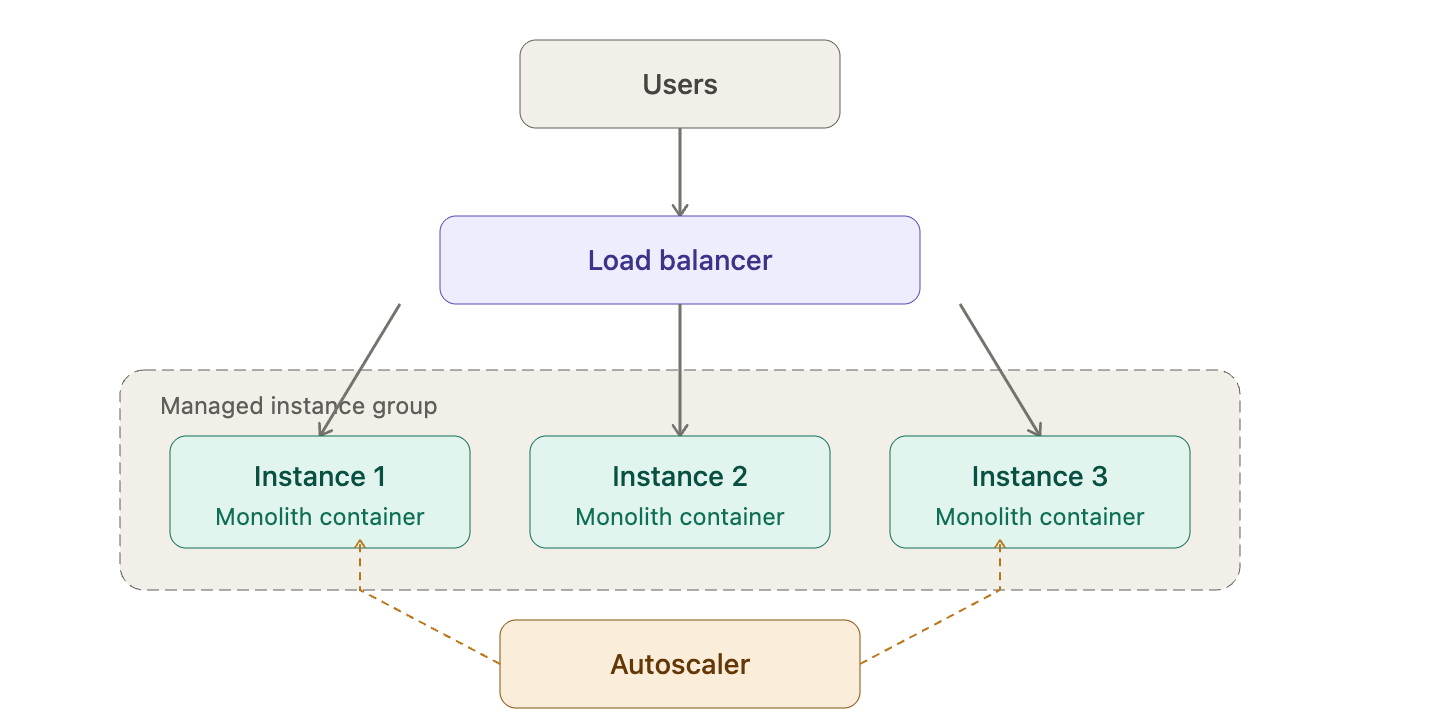
We containerized TechShip with Docker and moved to managed instance groups with autoscaling.
A load balancer distributed traffic. When CPU spiked, new instances spun up. When traffic dropped, they scaled back down. Costs finally matched usage.
What improved:
- Scale out instead of up, add instances as needed
- Pay only for what you use
- Failed instances replaced automatically
- No more single point of failure
What still hurt:
- Cold starts took minutes, users felt every spike before new capacity came online
- The app was still a monolith inside the container, one crashing module still took down everything
We fixed the infrastructure problem. The application problem remained.
Stage 3: Kubernetes — Microservices, Real Resilience
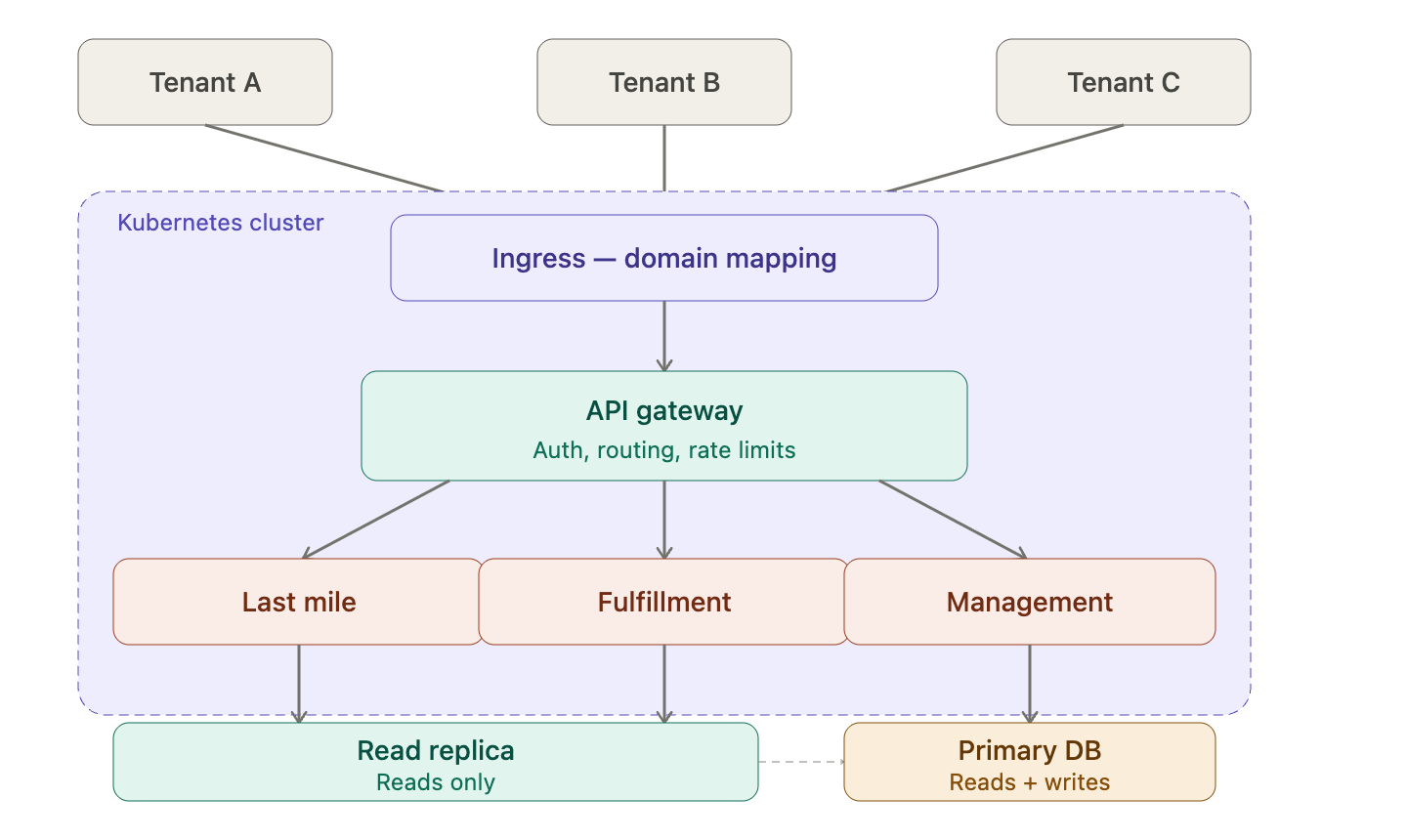
We broke the monolith into three services aligned with our core business domains: Last Mile, Fulfillment, and Management.
Each service deploys, scales, and fails independently.
How the architecture works:
- Tenants connect through an API Gateway: single entry point handling auth, routing, and rate limiting
- A Kubernetes Ingress maps each customer's custom domain to the right routing rules
- All three services share one database: a deliberate choice to avoid distributed transaction complexity at our scale
- Kubernetes handles the rest: starts containers, restarts failures, scales each service based on load
What changed:
- Last Mile crashes, Fulfillment and Management keep running
- Deploy one service without touching the others
- Scale only what's under load, not the whole platform
- Faster cold starts vs full VM provisioning
One bug no longer means everyone's down. The platform degrades gracefully instead of failing completely, and that's the whole point.
Key lessons
Start simple, plan ahead.
A single server was the right call at launch. But have a migration plan ready before you hit the wall not after.
Containerize early.
Docker unlocked everything autoscaling, Kubernetes, consistent deploys. If you're still running apps directly on servers, this is your next move.
Scale out, not up.
Adding instances beats buying bigger servers. Costs align with actual usage and there's no capacity ceiling.
Break the monolith when reliability matters.
It's the hardest migration, but independent services mean faster deploys, fewer outages, and a platform that degrades gracefully instead of going fully dark.